










Vous souhaitez vérifier qu’aucun contenu dupliqué, interne ou externe, ne risque d’entraver la bonne marche de votre référencement ? Découvrez quelques astuces pour très facilement et en quelques minutes seulement contrôler quelques facteurs de risque de duplicate content parmi les plus répandus.
1. Contrôler les versions avec et sans www
Bien que cette erreur soit de moins en moins constatée par nos équipes, il peut encore arriver sur qu’un site soit dupliqué, car accessible à la fois sur www.exemple.com et exemple.com
Pour écarter ce risque, tapez simplement dans votre barre d’adresse les deux variantes, avec et sans www. L’une doit rediriger vers l’autre. Ne vous contentez pas de la page d’accueil et validez votre première constatation en procédant de même avec quelques pages internes choisies au hasard.
Vérifiez aussi des variantes avec erreur, comme w.exemple.com. Si vous affichez la page demandée, et si aucune balise canonical vient sécuriser votre référencement, vous venez d’identifier une éventuelle faille pouvant être exploitée en négative SEO.
2. Identifier des versions de travail indexées
Les versions de développement ne doivent pas être indexées. Elles sont protégées par divers moyens, souvent couplés :
- robots.txt
- filtrage par IP
- demande de mot de passe
- …
Mais ce n’est pas toujours le cas, et il peut arriver que le site www.exemple.com voisine avec dev.exemple.com ou preprod.exemple.com
Pour identifier les risques de duplication involontaire, utilisez la syntaxe avancée de recherche sur Google.
Si votre version principale est développée avec www., tapez la commande suivante : site:exemple.com -www
 Ainsi, vous écartez des résultats toutes les pages de votre version principale. Vous pourrez ajouter dans votre syntaxe d’autres sous-domaines éventuels :
Ainsi, vous écartez des résultats toutes les pages de votre version principale. Vous pourrez ajouter dans votre syntaxe d’autres sous-domaines éventuels :

Vous pourriez voir émerger parmi les résultats des pages du type dev.exemple.com, preprod.exemple.com ou même xyz.exemple.com (les variantes avec erreur évoquées plus tôt).
3. Vérifier la qualité de la réécriture des URL
La réécriture des URL est souvent à la source de DUST (Duplicate Url Same Text). En effet, régulièrement, nous tombons sur des sites dont le contenu d’une page est accessible à deux URL. Vous devez notamment être attentif aux URL qui intègrent un ID unique :
- www.exemple.com/ma-page-geniale/ : ce type d’URL est rarement facteur de risque
- www.exemple.com/12345/ma-page-geniale/ ou encore www.exemple.com/ma-page-geniale-12345/ peuvent être à risque. C’est l’identifiant unique (12345) qui appelle le contenu spécifique à la page. Modifiez la partie descriptive présente dans l’URL et voyez si le contenu s’affiche. Par exemple, www.exemple.com/12345/testons-comme-des-fous/
La présence d’une balise canonical dans le code source (ctrl+U) peut corriger ces problèmes. Attention toutefois : celle-ci doit reprendre l’URL de la véritable page, et pas de la page affichée.
Par exemple, si vous constatez que les deux URL suivantes affichent le même contenu :
- www.exemple.com/12345-ma-page-geniale/
- www.exemple.com/12345-testons-comme-des-fous/
Vérifiez le code source des deux pages et assurez-vous que les deux pages partagent la même URL canonique : <link rel=”canonical” href=”http://www.exemple.com/12345-ma-page-geniale/” />
Soyez attentifs aux pages de recherches triées
Les sites e-commerce, les annuaires, les catalogues, les sites d’actualités ou les blogs offrent parfois des critères de tris. On peut choisir d’afficher les produits du moins cher au plus char, les articles du plus récent au plus ancien, etc…
Or, les pages triées sont très similaires. Vous devez donc vous assurer :
- que les pages triées ne renvoient pas sur une URL distincte
- s’il existe bien une URL distincte par page triée, vérifiez :
- que la page possède dans son code source une balise <meta name=”robots” content=”noindex”/>
- et/ou une balise canonical avec l’URL de la page non triée
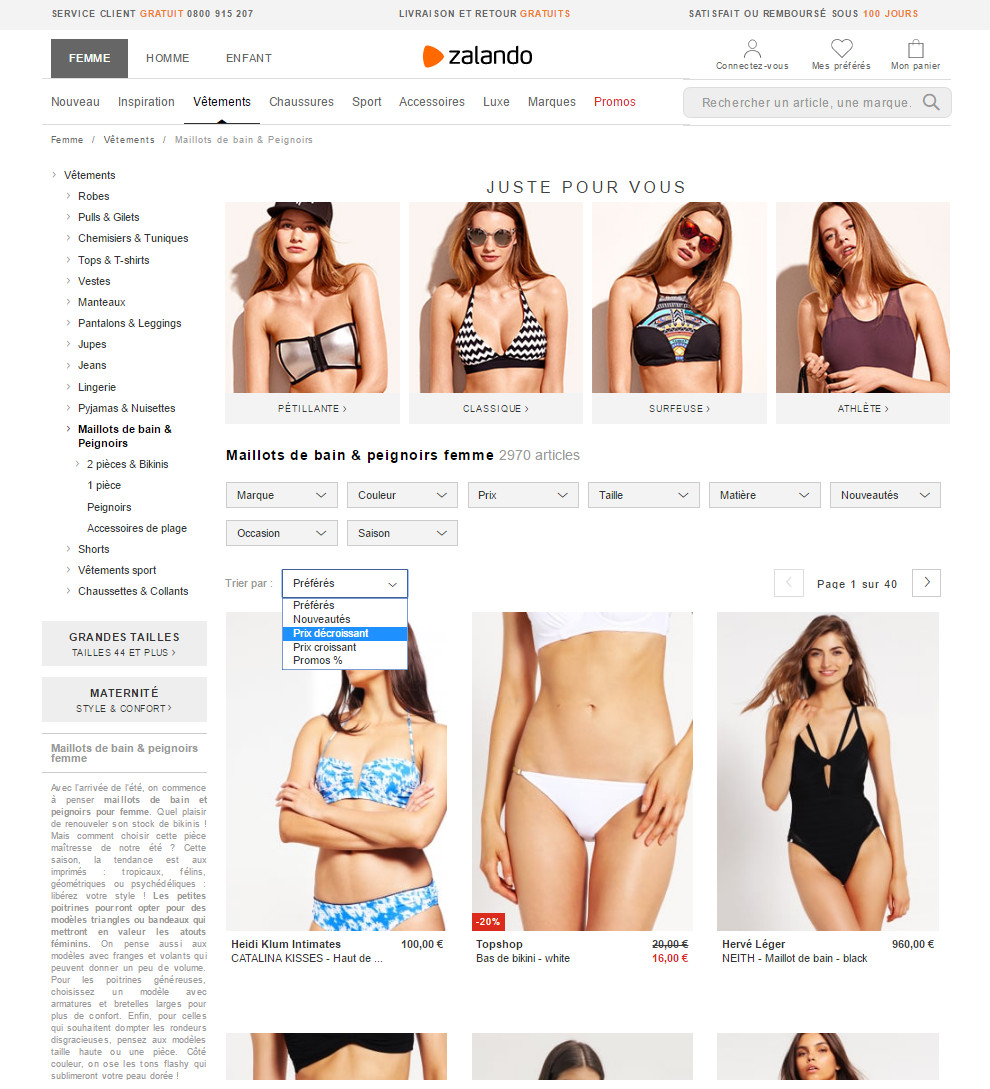 Un exemple de point de vigilance : les tris par popularité, date de sortie, prix, promotion…
Un exemple de point de vigilance : les tris par popularité, date de sortie, prix, promotion…
Une analyse superficielle du contenu dupliqué interne
Attention : ces quelques astuces peuvent écarter les facteurs de risque les plus courants. Mais cette analyse demeure très superficielle et incomplète. Elle ne doit en aucun vous exempter d’une analyse bien plus approfondie, réalisée par une agence spécialisée. Comme nous l’a fait remarquer Julien Deneuville sur Twitter, un crawl de site est en effet l’étape suivante pour creuser un peu plus la question.
Besoin d’aide ? Demandez un audit SEO à une agence spécialisée pour bénéficier d’un examen complet de votre site.
Des outils dédiés au contenu dupliqué vous feront gagner un temps précieux. Parmi les meilleures solutions sur le marché, citons https://www.killduplicate.com/fr. Kill Duplicate est un outil made in France (cocorico !). Il permet d’assurer une veille efficace et de détecter notamment en temps réel le vol de son contenu par d’autres sites web. Les abonnements sont accessibles pour un contrôle sur toutes vos pages ou un échantillon représentatif d’URL.
